Abstract
본 논문은 머리 자세 추정의 정확도를 향상시키기 위한 새로운 접근 방식을 제안한다. 제안된 방법은 원근 왜곡의 부정적 영향을 줄이기 위해 이미지 보정을 사용하고, 가벼운 합성곱 신경망을 통해 높은 정확도의 머리 자세 추정을 달성했다. 카메라의 광축과 얼굴 중심의 투영 벡터 사이의 각도를 계산하여 얼굴 이미지를 정위치화하고, 이를 입력으로 사용해 머리 자세를 추정한다. 실험 결과는 제시된 방법이 최신 기법에 비해 더 높은 정확도와 더 빠른 처리 속도를 달성함을 보여준다.
I. INTRODUCTION
최근, RGB 또는 RGBD 카메라와 같은 소비자용 이미지 기반 장비를 사용해 머리 포즈 추정을 더 단순하고 일반적인 방식으로 할 수 있는 기술이 개발됐다. 이 기술은 깊이 정보를 사용하여 정확도를 향상시키긴 했지만, 특별한 장비가 필요하고 사용할 수 있는 상황이 제한적이라는 문제를 가지고 있다. 이러한 문제를 해결하기 위해, 얼굴 이미지로부터 직접 머리 포즈를 추정하는 새로운 접근법이 개발되었으며, 이는 랜드마크 기반 방법과 랜드마크 비기반 방법으로 나뉜다. 특히, 랜드마크 비기반 방법은 환경 변화나 얼굴의 가림에도 강인한 성능을 보이는 컨볼루션 신경망(CNN)을 사용하여 주목받고 있다.
II. RELATED WORK
랜드마크 기반 방법과 랜드마크 비기반 방법은 RGB 이미지 기반 머리 포즈 추정을 위한 두 가지 주요 접근법이다.
1) 랜드마크 기반방법
- 얼굴 랜드마크 사이에 내포된 기하학적 관계를 조사하여 머리 자세를 추정
- 2D 투영을 통해 3D 자세를 결정할 수 있다는 개념을 기초로 함
- 랜드마크를 사용하여 인간의 얼굴을 모델링하고, 구축된 모델을 통한 머리 자세 추정
단점
- 효율적인 얼굴 랜드마크 예측 모델이 필수적으로 요구됨
- 얼굴 랜드마크의 깊이 정보 활용을 위해 개인별로 사전 정의된 얼굴 모델이 필요
- 모델이 실제 얼굴과 완전히 일치하지 않을 경우, 추정된 자세에 오류가 발생
2) 랜드마크 비기반 방법
- 전체 얼굴 이미지를 탐색하고 이미지의 강도로부터 직접 머리 포즈를 추정
- 기계 학습 기술의 발전, 특히 딥 러닝의 비약적인 발전을 통해 활발히 연구됨
- CNN 사용을 통한 전체 얼굴 이미지의 특성을 학습하고 머리 자세를 회귀 진행
- ResNet50을 머리 자세 예측에 사용하여 공동 자세 분류와 회귀를 통해 정확한 결과를 달성
- 비디오 프레임에서 머리 자세를 예측하기 위해 VGG 네트워크를 사용
단점
- 얼굴 이미지가 약한 원근 투영을 사용하여 형성된다는 비현실적인 가정에 기반을 둠
- 얼굴 중심이 카메라의 광축에서 멀어질수록 완전원근 투영과 약한 원근 투영을 사용한 투사된 이미지가 현저하게 다름
- 얼굴 중심이 광축에서 멀어질수록 근사 오차가 증가
머리가 광학 축 또는 이미지의 중심에 가까울 때, 현재 머리 포즈 추정 방법의 정확도는 매우 좋다. 왜냐하면 투시 왜곡이 무시할 수 있을 정도로 작기 때문이다. 반면, 머리가 Fig 2. 처럼 카메라 광학 축으로부터 멀어지고 투시 왜곡이 더 분명해질 때, 이러한 방법의 성능은 저하된다.

- a) : 머리가 카메라 좌표계와 완벽하게 정렬되어 있으며 Roll, Pitch, Yaw 전부 0
- (b) : 머리가 카메라에서 z축을 따라 멀어지면서 투영된 이미지가 변함
- (c) : 머리가 카메라의 x축을 따라 이동할 때, 머리의 모습은 Yaw 회전으로 인식
- (d) : 머리가 카메라의 y축을 따라 이동할 때, 머리의 모습은 Pitch 회전으로 인식
III. IMAGE RECTIFICATION
본 논문에서는 투시 왜곡의 영향을 줄이기 위해 이미지 보정 기법을 사용하고, 머리 포즈 추정을 위한 경량 CNN을 설계하는 방법을 제안한다. Fig 3. 과 같이 머리 중심이 카메라 좌표계와 정렬되지 않은 상태에서 캡처된 입력 이미지를 수학적으로 보정하여, 머리 중심이 가상 카메라 좌표계의 광학 축과 정렬되도록 한다.
이미지 보정 플로우
- Co : 실제 카메라 시스템
- CR : 머리 중심이 가상 광학 축과 정렬된 가상 카메라 시스템
- 입력 이미지에서 얼굴을 탐지하고, 얼굴 경계 상자의 중심을 머리 중심으로 사용
- 입력 이미지에 탐지된 얼굴 영역은 perspective wraping을 통해 가상 카메라 시스템 CR로 변환
- wraping이 진행된 뒤, 보정된 이미지의 머리 중심은 가상 광학 중심과 정렬됨
- 보정된 이미지의 얼굴 영역은 추정 네트워크의 입력으로 사용되어 가상 카메라 시스템 CR에서 머리 포즈를 추정
- 추정 네트워크의 출력은 최종 머리 포즈 추정으로서 카메라 좌표계 CO로 변환
※ perspective warping : 이미지 처리에서 특정 이미지 영역을 새로운 관점에서 볼 수 있도록 변환하는 기법
A. Camera System Transformation
컴퓨터 비전 시스템에서 머리 포즈 추정을 위해 이미지 보정을 사용하는 방법을 설명한다. 여기에는 이미지의 왜곡을 수정하고 가상 카메라 시스템에 맞춰 머리 중심을 정렬하는 과정이 포함된다. 주요 과정을 살펴보면,
1.카메라 시스템 CO : 실제 카메라 시스템으로, 핀홀 카메라 모델을 통해 이미지 평면 PO에 투영됨
2. 이미지 왜곡: 얼굴이 카메라의 광학 축에서 벗어나 있을 때 발생하며, 이로 인해 머리 포즈 추정에 오류가 생김
3. 이미지 보정 : 카메라를 회전시켜 실제 머리 중심을 가상 카메라 시스템 CR의 광학 축과 일치시킴
4. 보정 이미지 생성 : 입력 이미지의 얼굴 영역은 가상 이미지 평면 PR으로 변환되어 보정된 이미지를 생성하며, 이 보정된 이미지에서 머리 포즈 추정이 수행됨
※ 카메라 광학 축 : 카메라 렌즈의 중심을 통과하고, 이미지 센서의 중앙과 정렬되는 가상의 직선
5. 회전 축 벡터 r와 회전 각도 θ : 카메라 시스템 CO와 가상 카메라 시스템 CR 사이의 변환을 정의하는 회전 행렬은 CO에서 얼굴의 중심을 CR의 광학 축 위로 변환하기 위해 계산되어야 한다.
- r : 회전 축 벡터
- θ : 얼굴 이미지 보정을 위해 3D 공간에서 회전시켜야 하는 각도
- uz : CR의 z축에 단위 벡터
- ez : Co의 z축에 대한 단위 벡터
6. 카메라 투영 행렬 : K = [fx, 0, cx ; 0, fy, cy ; 0, 0, 1]
- fx, fy : x방향 y방향의 카메라 초점거리
- cx, cy : 이미지 광학 중심의 위치
7. 머리 중심의 동차 좌표 : p = [px, py, 1]T
- px, py : 입력 이미지에서 머리 중심
- c : Co 에서 머리 중심의 3D 위치
- c = [xc, yc, zc]T

8. 3D 투영
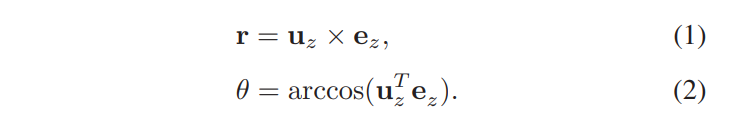
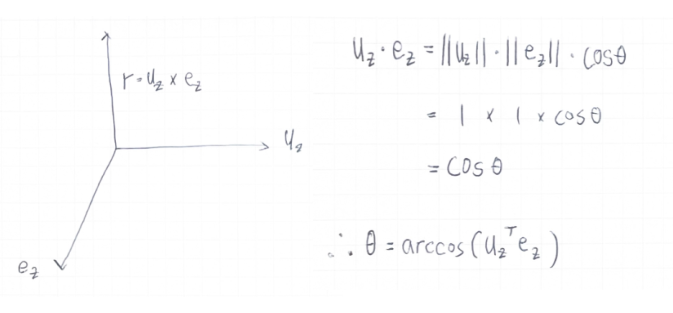
9. 회전 행렬 MO→R : 실제 카메라 시스템과 가상 카메라 시스템 사이의 변환을 정의하며, 로드리게스 회전 공식 (3)을 사용하여 계산된다.
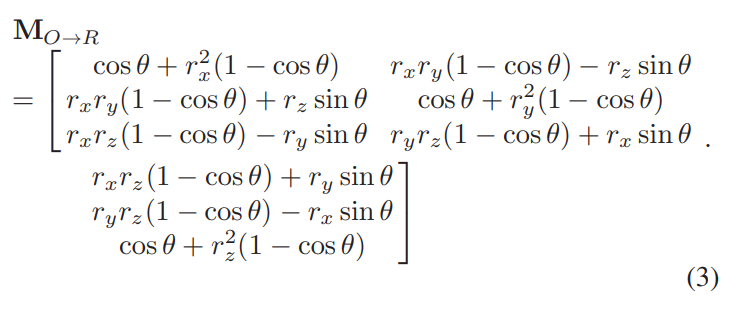
위 과정은 입력된 얼굴 이미지의 왜곡을 수정하여 머리 포즈를 더 정확하게 추정할 수 있도록 한다. 보정된 이미지는 머리 포즈 추정을 위해 사용되고, 결과는 실제 카메라 시스템에 적용할 수 있도록 다시 변환된다.
B. Image Reprojection
위에서 살펴봤던 회전 행렬 MO→R을 사용하면 입력 이미지의 얼굴 영역을 가상 카메라 시스템 CR의 가상 이미지 평면(PR)에 변환하여 카메라 시스템 CR에서 보정된 얼굴 이미지를 계산할 수 있다. Fig. 4. 는 이 과정을 설명한다.
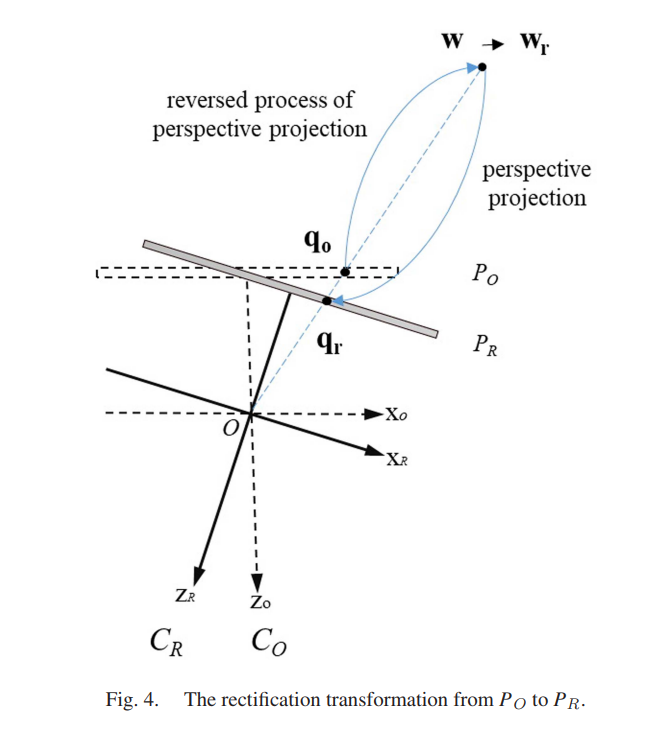
STEP
역투영의 가정
- 입력 이미지의 각 픽셀의 깊이(즉, 카메라로부터의 거리)가 알려져 있다고 가정
- 깊이 정보를 정확히 알 수 없기 때문에, 이를 추정하는 방법이 사용됨
1단계: 3D 점의 변환
- 입력 이미지의 얼굴 영역에 있는 모든 픽셀이 3D 공간으로 역투영되어 3D 점 w를 생성
- 3D 점 w는 가상 카메라 좌표 시스템CR 로 변환되기 위해 회전 행렬 MO→R을 사용하여 변환
- K : 카메라 투영 행렬(카메라의 내부 매개변수, ex 초점 거리, 주점)
- MO→R을 사용하여 변환을 통해 3D 점 wr을 얻음
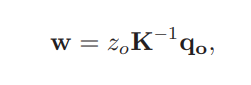
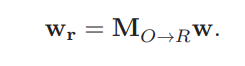
2단계: 가상 이미지 평면으로의 투영
- 변환된 3D 점 wr은 가상 카메라 시스템 CR의 가상 이미지 평면 PR에 full-perspective 투영
- 카메라 시스템 CO와 가상 카메라 시스템 CR은 동일한 카메라 투영 행렬 K를 공유
- 투영 과정을 통해 픽셀의 동차 좌표 qr이 계산
- 아래 식을 통해 scale이 결정됨
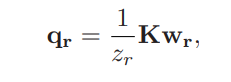
3단계: 전체 보정 과정의 공식화
- 결정된 scale을 통해 이미지간의 비율차이를 알 수 있게 되었으므로 전체 보정 과정을 공식화 할 수 있음
- 이미지 스케일 시 (z-축) 정보를 잃게 되기 때문에, 실제 깊이 zo 값은 알 필요 없음
- 변환 행렬 T 에 내장된 비율만을 직접적으로 필요
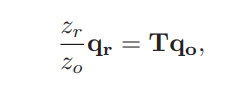
4단계: 보정된 이미지의 생성
- 입력된 얼굴 이미지의 모든 픽셀이 가상 카메라 시스템 CR의 가상 이미지 평면에 투영되어 보정된 얼굴 이미지를 얻음
- 보정 전후의 샘플 이미지를 통해 보정의 효과를 확인
보정 결과

- 첫번째 열 :보정 전 이미지
- 두번째 열 : 보정 후 이미지
- 격자선 : 보정 효과
C. Head Pose Transformation
머리 자세 추정은 보정된 이미지 내에서 즉, 가상 카메라 좌표계 내에서 수행된다. 그러므로 데이터셋에서 제공하는 실제 머리 자세는 우리 네트워크 훈련과 CR에서의 머리 자세 추정을 위해 가상 카메라 시스템 CR로 변환되어야 한다. 하지만, 머리 자세 추정 알고리즘의 정확도를 평가하기 위해서는, 우리 네트워크에서 추정된 머리 자세를 다시 실제 카메라 시스템 CO로 변환하여 정확도 평가를 수행하기 때문에 오일러 변환을 통해 회전 행렬의 형태로 변환시킨다.
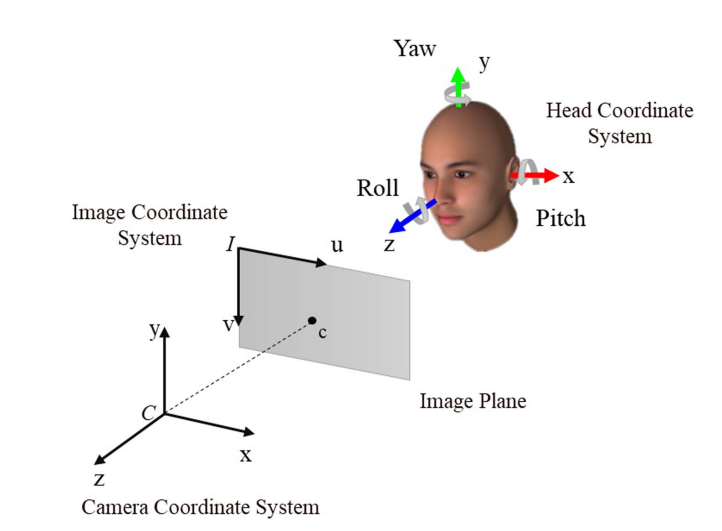
MR은 회전 행렬 MO→R을 사용하여 다음과 같이 계산
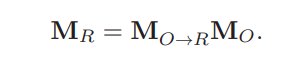
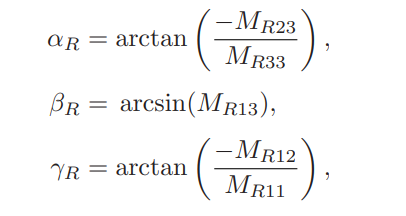
- itch(x) : αR = arctan(−MR23 / MR33)
- yaw(y) : βR = arcsin(MR13)
- roll(z) : γR = arctan(−MR12 / MR11)
테스트를 위해서는 데이터셋의 모든 테스트 이미지도 CO에서 CR로 보정되거나 변환되어야 한다. 보정된 테스트 이미지들은 더 나은 머리 자세 추정을 위해 추정 네트워크에 사용된다. 본 논문의 네트워크는 CR에서 훈련되기 때문에, 네트워크에서 출력되는 머리 자세 추정(오일러 각도 측면에서) 또한 CR에 있다. 행렬 형태의 머리 자세 추정은 아래의 식을 사용하여 카메라 좌표 시스템 CO로 다시 변환된다.
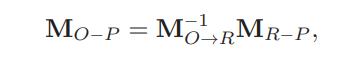
4줄 요약
- 실제 카메라 시스템 CO에서 촬영된 이미지는 머리가 광학 축에서 벗어나 있을 수 있으므로, 왜곡이 있을 수 있다.
- 이 왜곡을 수정하기 위해, 이미지는 가상 카메라 시스템 CR으로 변환되어 보정다. 이 과정에서 이미지는 가상의 광학 축에 맞춰진다.
- 보정된 이미지에서는 머리 자세를 추정하게 되며, 이 추정된 자세는 가상 카메라 좌표계 CR에 기반한다.
- 추정된 머리 자세를 최종적으로 평가하거나 실제 사용을 위해서는, 이를 다시 실제 카메라 시스템 CO의 좌표계로 변환한다.
IV. ESTIMATION NETWORK
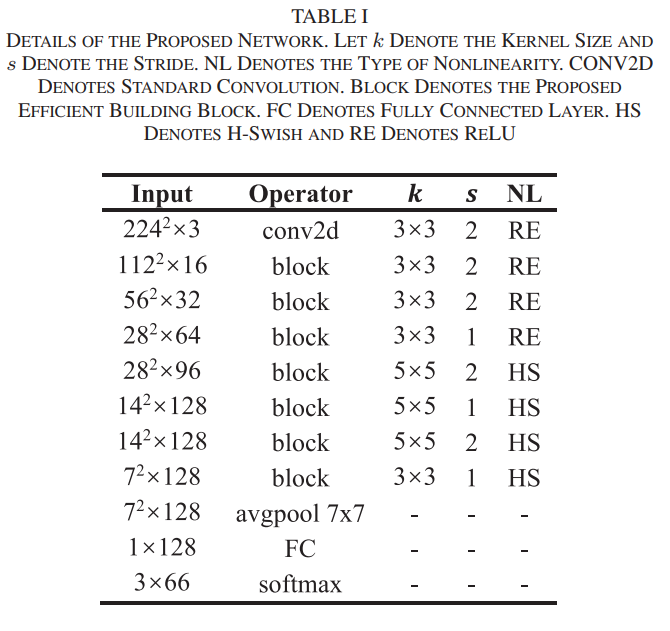
경량화된 합성곱 신경망은 보정된 이미지로부터 머리 자세를 추정하기 위해 설계되었다. 제안된 네트워크는 그룹 합성곱과 깊이별 분리 합성곱 기술(Depth separable convolution)을 기반으로 한다. 그룹 합성곱과 깊이별 분리 가능 합성곱 기술을 반복적인 빌딩 블록에서 사용하는 것은 많은 CNN 기반 인식 알고리즘에서 경량 네트워크를 구축하는 효율적인 방법이다.
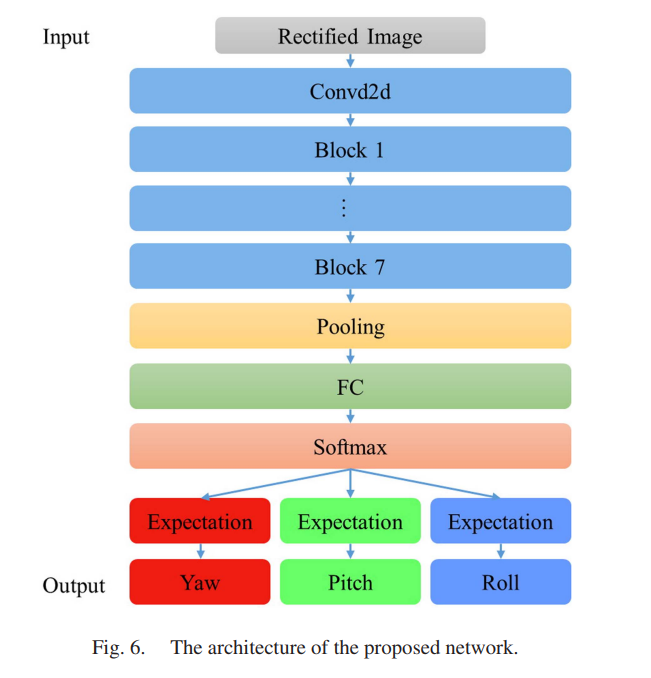
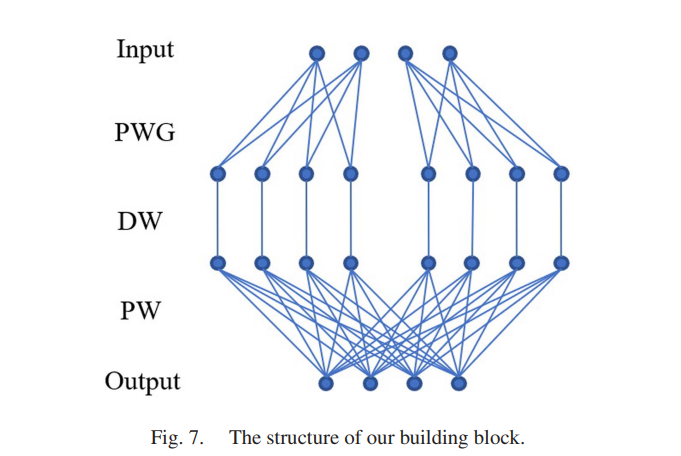
Depth separable convolution(Depth-wise conv + Point-wise conv) 구조 사용
- 비선형성이 너무 많은 정보를 잃어버리는 것을 방지하기 위해 확장 레이어 사용이 중요
- Point-wise convolution
- 1x1 합성곱이라고도 불리며, 특징 맵의 각 위치에서 채널 간 정보를 섞는 데 사용
- 모든 입력 채널에 걸쳐 1x1 커널을 적용하여 새로운 특징을 만들어내는 과정
- 계산 비용이 낮고, 채널 차원의 특징을 결합하여 네트워크의 깊이를 늘릴 때 효과적
- Point-wise group convolution
- PWG는 PW를 그룹화하여 수행하는 연산으로, 입력 채널을 그룹으로 나누고 각 그룹에 대해 별도의 1x1 합성곱을 적용
- 표준 PW 합성곱에 비해 파라미터의 수와 연산량을 줄이기 위한 방법으로 사용
- 그룹 합성곱은 채널을 여러 그룹으로 나누고 각 그룹 내에서만 합성곱을 수행하므로, 각 그룹 간 정보 교환이 제한됨
- 각 합성곱 층은 배치 정규화 연산과 활성화 레이어를 따름
ReLU 와 h-swish 2가지 활성화 함수 사용
- 모델 정확도와 계산 비용 사이에 더 나은 균형을 달성하기 위해 사용
B. Discriminative Loss Function
각 이미지에 대한 손실의 가중치
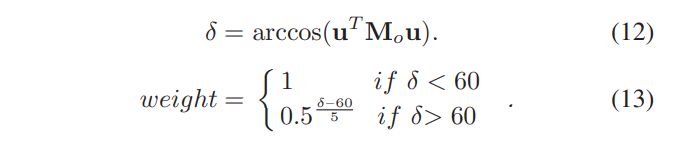
- 각 이미지의 네트워크 출력에 대한 손실을 나타내기 위해 교차 엔트로피 손실과 MSE 손실의 합을 사용
- 각 배치에서 각 이미지의 손실에 대한 가중치를 설정
- δ를 카메라 좌표계의 z축과 머리 좌표계의 z축 사이의 각도(도 단위)로 나타냄 ※ u : [0, 0, 1]T
- 각 이미지에 대한 손실의 가중치를 얻기 위해, 우리는 δ를 [0, 1] 범위로 정규화
각 오일러 각도에 대한 손실 함수
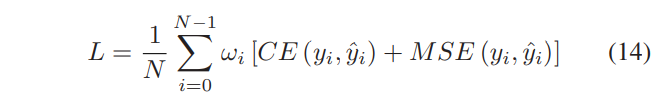
- CE : 교차 엔트로피
- MSE : 평균 제곱 오차 손실 함수
- N : 데이터의 한 배치에 있는 이미지의 수
- ωi : i 번째 이미지에 대한 손실의 가중치
- yi : i 번째 이미지의 실측값
- y^i : 추정 결과
L Total Value
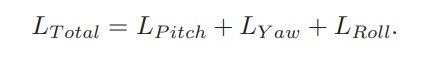
V. EXPERIMENTS AND DISCUSSION
A. 데이터셋 및 그 실측값
본 논문의 실험에서는 3D정보를 유일하게 포함하고 있는 BIWI 데이터셋 과 다른 두 데이터셋인 300W-LP와 AFLW2000은 2D 이미지에서 추정된 머리 자세를 실측값으로 사용한다.
B. 설정 및 평가 지표
머리 자세 추정을 위한 얼굴감지는 DSFD를 사용하여 수행되었고, 얼굴 경계 상자 중심이 머리 중심을 근사하는 데 사용되었다.
- 초기 학습률 : 0.001
- β1=0.9 및 2=0.999를 가진 Adam 최적화를 사용
- 70 epochs 동안 훈련
- 데이터 증강을 위한 훈련 이미지에 대해 무작위 자르기, 무작위 다운샘플링 및 무작위 스케일링 적용
ImageNet 평균 및 표준 편차를 사용한 정규화
세 가지 실험 모두에서 두 가지 평가 지표가 사용되었다.
- 요, 피치, 롤 각도의 평균 오차
- 평균 절대 오차(MAE)
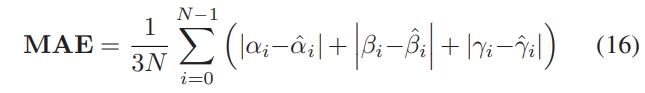
- N : 테스팅 데이터 셋의 샘플 수
- (αi, βi, γi) : 실측된 오일러 각도이고
- (α^i, β^i, γ^i) : 추정된 오일러 각도
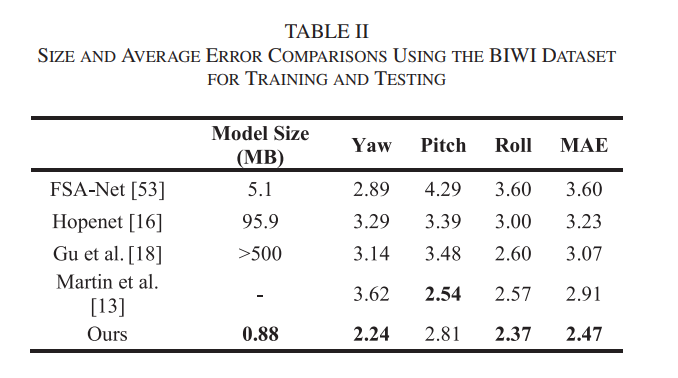
C. Experiment I
- BIWI 데이터셋을 훈련용 70% (16개 비디오)와 테스트용 30% (8개 비디오)로 무작위 분할
- 위 과정을 세 번 반복하고 평균 측정 오류를 측정
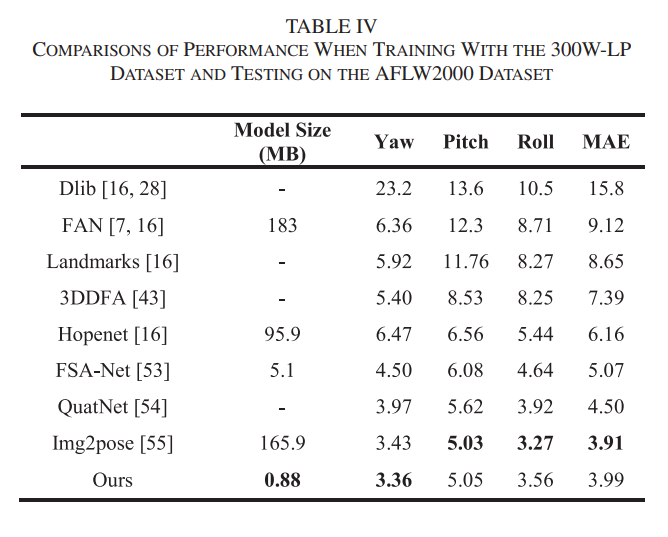
D. Experiment II
- 300W-LP나 AFLW 데이터 셋으로 훈련 및 BIWI Dataset으로 테스트 진행
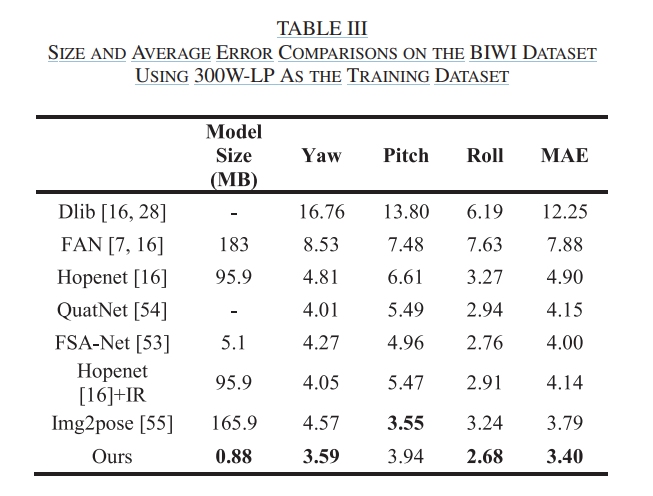
E. Experiment Ⅲ
- 300W-LP 데이터셋에서 훈련 및 AFLW2000 데이터셋에서 테스트 진행
Significance of Contributions
- 이미지 보정 및 차별화된 가중치 손실 함수의 중요성을 보여주기 위해 실험 진행
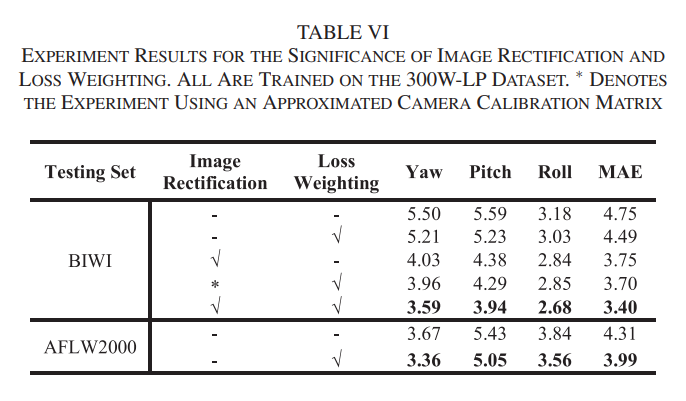
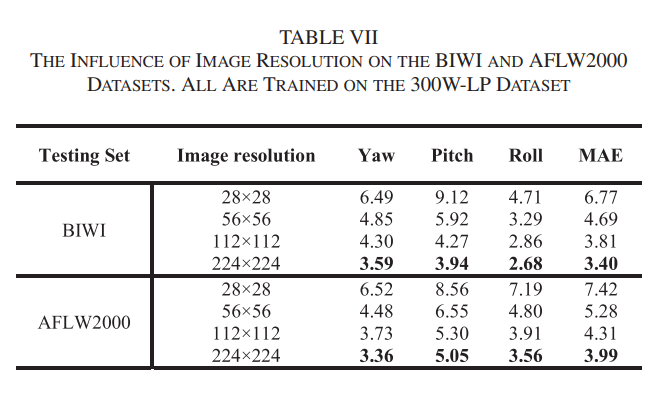
Image resolution Experiment
- 224 x 224 일때 가장 성능이 높게 나옴
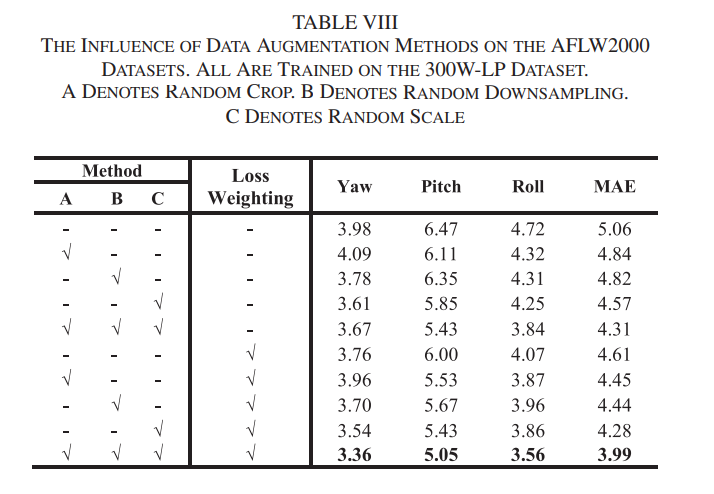
Data Augmentation 및 손실 가중치 함수의 사용 유무 실험
- 전부 적용했을 때 성능이 가장 높게 나옴
VI. CONCLUSION
본 논문은 큰 원근 왜곡을 가진 얼굴 이미지가 머리 자세의 정확도를 저하시킨다는 문제를 해결하기 위해 이미지 보정을 포함하는 경량 네트워크 접근 방식을 제안했다. 보정을 통해 머리 중심을 카메라 좌표계와 정렬시켜 머리 자세 추정의 정확도를 향상시켰으며, 차별화된 가중치 손실 함수를 사용하여 네트워크를 훈련시켰다. 실험 결과는 이미지 보정과 가중치 손실 함수가 정확도를 개선하는 데 기여함을 보여주며, 세 가지 인기 있는 데이터셋에서 최신 방법들을 능가했다. 또한, 본 네트워크는 GPU와 CPU 플랫폼에서 높은 처리 속도를 달성함을 확인했다.
'논문' 카테고리의 다른 글
| Physics-based Deep Learning - Supervised Training (2) | 2024.03.26 |
|---|---|
| [논문] AAM Based Facial Feature Tracking with Kinect (0) | 2024.03.25 |
| [논문] ImageNet Classification with Deep Convolutional Neural Network (0) | 2024.03.25 |
| [논문] RGB-D camera pose estimation using deep neural network (0) | 2024.03.18 |
| Physics-based Deep Learning - Overview (0) | 2024.03.15 |