https://www.researchgate.net/publication/282796794_AAM_Based_Facial_Feature_Tracking_with_Kinect
Abstract
본 논문은 Kinect에서 얻은 깊이(Depth) 데이터를 활용하여 AAM(Active Appearance Model, 활성 외형 모델)의 시야각 변화 문제를 해결하는 방법을 제시한다. 깊이 데이터로 머리 포즈 정보를 얻고, 이를 바탕으로 3D 얼굴 그리드 모델을 초기화 및 조정하여 얼굴 특징을 정확히 추적한다. 이 방법은 머리를 회전할 때의 AAM 성능을 향상시킨다.
※ AAM : 이미지 내의 객체, 특히 얼굴의 형태(shape)와 외형(appearance)을 동시에 모델링하는 컴퓨터 비전 기술
1. Introduction
얼굴 특징 추적은 중요한 기술이며, 이를 위해 주로 AAM(Active Appearance Model)이 사용된다. AAM은 새 이미지에 객체의 형태와 외형을 맞추는 알고리즘이며, 최근에는 효율성과 강인성을 개선하는 연구가 진행되고 있다. 그러나 시야각 변화 문제를 해결하지 못해, 이를 극복하기 위해 2D 및 2D+3D 포즈 정보를 활용한 다양한 연구가 진행되고 있다. 특히 최근에는 Kinect와 같은 도구를 활용하여 깊이 정보를 이용한 얼굴 특징 추출이 선호되며, 이를 통해 얼굴 특징 위치를 보다 정확하게 매칭할 수 있다. 얼굴 특징 매칭의 정밀도와 강인성은 매우 중요하며, 조명과 포즈 변화로 인한 오류가 주요 문제로 인식된다. Kinect의 적외선과 3D 깊이 데이터는 이러한 문제를 해결하는 데 도움을 줄 수 있으며, 깊이 정보는 포즈 정확도를 향상시킨다.
본 논문에서는 두 가지 작업을 수행한다.
1) 추가적인 깊이 이미지를 사용하여, 방법은 깊이와 RGB 이미지 사이의 픽셀을 연결하고 얼굴 3D 그리드 모델과 뷰 기반 AAM 모델을 설정
2) 머리가 회전될 때 AAM을 적절하게 초기화
논문 개요는 Fig 1과 같이 준비 및 실행 시간 두 부분이 포함되어 있다. Preparation 부분은 사전적으로 진행되며, 뷰 기반 모델 훈련과 머리 자세 회귀 포레스트 훈련을 포함한다. Run-Time은 실시간으로 진행되며, 매칭 과정을 포함한다.

2. Active Appearance Model(AAM)
AAM은 통계 모델과 입력 이미지의 외관을 사용하여 얼굴의 모양을 추정한다. 모델을 모양과 외관 두 부분으로 나누고, 두 부분 모두가 선형 공간의 조합으로 얻어질 수 있다고 가정한다.
모양 구하기
AAM의 모양은 2D 삼각화된 메쉬로 정의되고, 모양 S는 메쉬를 구성하는 n개의 꼭짓점의 x 및 y 좌표로 정의된다: S = (x1, y1, …, xn, yn)T 이를 표현한 간결한 선형 모델은 다음과 같다.
$$ S = S_{0} + \sum_{i=1}^{m}p_{i}S_{i}, $$
- pi : 모양 매개변수
- S0 : 평균 모양
- Si : m개의 가장 큰 고유값
외관 구하기
$$ A = A_{0} + \sum_{i=1}^{l}q_{i}A_{i}(x), $$
- qi : 외관 매개변수
- A0 : 평균 외관
- Ai : l개의 가장 큰 고유값
PCA(주성분 분석) 진행
훈련 이미지의 모양과 외관에 PCA(주성분 분석)를 적용한 후, Si와 Ai를 획득할 수 있다. AAM은 얼굴에 모양을 맞추어 최소화한다. AAM 알고리즘은 실제 외관과 예측 외관의 잔차 오차를 계산한 다음, 오차를 최소화하기 위해 반복적으로 조합 계수 C를 최적화한다. 최종적으로 계수는 얼굴 특징의 모양을 얻기 위해 사용된다.
$$ arg min\left ( \sum_{x\epsilon S_{0}} \left [ A_{0}(x) + \sum_{i=1}^{m}q_{i}A_{i}(x)-I(N(W(x;p))\right ]^{2} \right )\cdot $$
- C = {p, q, u}
- p : 모양 매개변수
- q : 외관 매개변수
- u : 변환, 회전 및 스케일링 매개변수
- W : Weight
- N : Network
3. Preparation-view based models and head pose estimate model
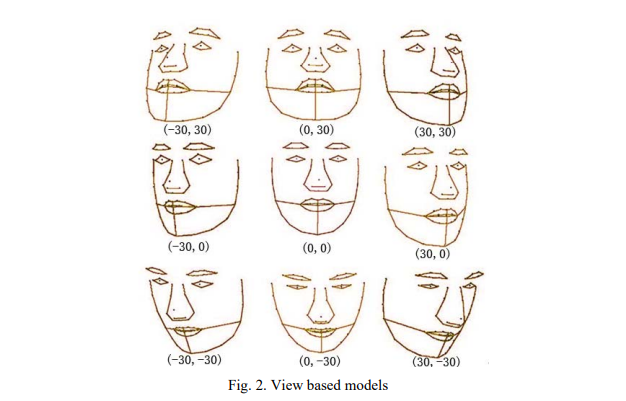
3.1. View based models
AAM 훈련을 위해 Biwi Kinect Head Pose Database를 사용한다. 이 데이터베이스에는 RGB와 깊이 데이터를 포함한 15,000개 이상의 이미지가 있으며, 대부분의 이미지는 비슷하므로 수동으로 약 200개의 이미지만 레이블을 지정한다.얼굴의 시각을 나타내기 위해 근사적인 정상 얼굴 평면을 사용하며, 이미지를 9개의 시점으로 나누어 9개의 시점 기반 모델을 훈련한다. 각 부분은 머리 자세의 각도 범위에 대해 별도의 AAM 모델로 훈련된다.
3.2. Head pose estimate model
본 논문은 Kinect 깊이 데이터를 기반으로 한 차별적인 랜덤 회귀 포레스트를 사용하여 머리 자세의 각도와 머리 중심을 추정하는 방법을 사용한다. 각 노드를 분할하여 클래스 레이블 분포의 Shannon 엔트로피와 머리 위치 및 방향의 분산을 동시에 줄이도록 훈련된 랜덤 트리를 설정한다.
4. Run time − initialization and match based on facial 3D grid model
4.1. Facial 3D grid model
얼굴 3D 그리드 모델 설정은 RGB 카메라 좌표계에서 얼굴 특징의 3D 좌표를 추출하는 과정이다. 각 카메라는 고유한 카메라 좌표계와 이미지 좌표계를 갖는다. 먼저, AAM을 사용하여 RGB 이미지에서 얼굴 특징을 추출한 다음, RGB로 깊이를 투영하여 작은 근접 영역에서의 깊이 값을 평균화하여 이러한 특징의 3D 좌표를 계산한다.
- Kinetic : RGB와 Depth 두 개의 카메라로 구성
- ARGB, Ad : 내부 매개변수
얼굴 특징 추출 과정
얼굴은 표정이 없는 정면이 이상적이며, 정면이 아닐 경우 머리 포즈 추정을 통해 적절한 모델을 선택하여 얼굴 특징을 추출해야 한다. 추출된 얼굴 특징은 RGB 이미지 좌표 체계에 위치하지만, 이를 RGB 카메라 좌표 체계로 변환하는 과정이 필요하다.
- PRGB : 카메라 좌표 체계에서의 특징점 좌표
- Pd : 깊이 카메라 좌표 체계에서의 특징점 좌표
- PRGB’ : RGB 이미지 좌표 체계에서의 특징점 좌표
- Pd’ : 깊이 이미지 좌표 체계에서의 특징점 좌표
- Od : 깊이 카메라 좌표 체계의 원점
- ORGB : RGB 카메라 좌표 체계의 원점

PRGB를 얻는 방법
주어진 PRGB’를 알고 있을 때 다음과 같은 방법으로 중간 좌표 Pd를 이용하여 얻을 수 있다.
$$ P_{RGB} = R\cdot P_{d} + T, $$
- R, T : 외부 파라미터의 회전과 이동
$$ P_{RGB}(Z) = r_{31}\cdot P_{d}(X)+r_{32}\cdot P_{d}(Y)+r_{33}\cdot P_{d}(Z), $$
- {r31, r32, r33} : R의 세 번째 행
- {t3} : T의 세 번째 행
- Pd(Z) : 깊이 이미지의 얼굴 영역의 모든 픽셀을 RGB 이미지로 투사한 다음, 작은 이웃 영역에서 얼굴 특징 PRGB 주변의 이러한 점들의 가중 평균을 계산한 값
$$ Pd(Z) = \frac{1}{\sum w_{i}}\sum w_{i}\cdot Z_{i} $$
Zi : 깊이 이미지에서 i번째 픽셀의 깊이 값
wi : 가중치, 주로 i번째 픽셀의 RGB 이미지에서 PRGB까지의 거리에 따라 달라짐
∑wi : 모든 가중치의 합계
Pd(Z)를 저렇게 구하는 이유?
→ 깊이와 RGB의 픽셀은 일대일 대응 관계에 있지 않고, RGB 이미지 좌표를 통해 깊이 카메라 좌표를 직접 찾을 수 없기 때문이다.
$$ P_{RGB}' = A_{RGB} \cdot P_{RGB}, $$
2차원 이미지 상의 좌표를 실제 3차원 공간 상의 좌표로 변환하는 과정, 위 식을 통해 PRGB(x), PRGB(y) 를 구할 수 있다.
- ARGB : 내부 파라미터
- 모든 얼굴 특징의 RGB 카메라 좌표를 얻고 얼굴 그리드를 생성
- 그리드 중심을 RGB 센서 카메라에서의 머리 중심의 투영 위치로 이동
- 위 과정을 거치면 얼굴 3D 그리드 모델을 얻을 수 있음
4.2. Initialization
초기화는 2단계를 통해 이루어진다.
1) 기반 모델 선택
- 머리 포즈 추정 방법을 사용하여 새로운 프레임에 대한 회전 행렬 R과 머리 중심 T를 얻음
- 회전 값(Rotation)을 이용하여 근사된 기반의 AAM(Active Appearance Model) 모델을 선택
2) AAM의 반복 초기값 초기화
- 첫 번째 단계 후, 회전 행렬 R과 머리 중심 T를 사용하여 얼굴의 3D 그리드를 변환
- 내부 파라미터를 사용하여 그리드를 RGB 이미지 평면으로 투사
- 마지막으로, 투사된 결과를 AAM의 초기값으로 사용
변환과 투사의 수식 및 결는 다음과 같다.
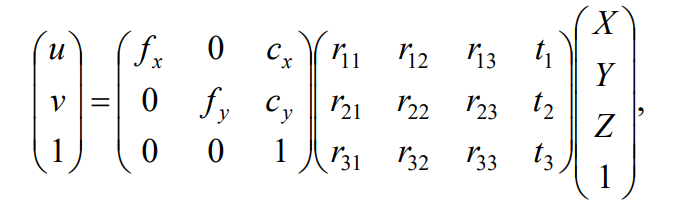
- (X, Y, Z)T : 얼굴 3D 그리드의 한 꼭짓점
- fx, fy : **픽셀 단위로 표현된 초점 거리
- cx, cy : 이미지 중심에 위치하는 주점

4.3. Match
초기화 후, 선택된 기반 AAM 모델을 사용하여 결과를 매칭한다. 매칭 알고리즘은 10개의 단계를 통해 구성된다.

- 단계 1. 비디오 시퀀스의 각 프레임 f를 순차적으로 처리
- 단계 2. 첫 번째 프레임이고 얼굴을 포함하는 경우
- 단계 3. 얼굴 3D 그리드 모델을 구축
- 단계 2. 첫 번째 프레임이고 얼굴을 포함하는 경우
- 단계 4. 첫 번째 프레임이 아니거나 얼굴이 포함되지 않은 경우
- 단계 5. 회귀 포레스트로 머리 포즈 (R|T)를 얻음
- 단계 6. 얼굴 3D 그리드를 회전시키고 이동시킨 후 RGB 카메라 평면에 투사
- (X, Y, Z)T → (u, v)T
- 단계 7. 기반 AAM 모델을 선택
- 단계 8. 투사 결과로 초기화
- 단계 9. AAM을 사용하여 형태 계수 C를 계산
- 단계 6. 얼굴 3D 그리드를 회전시키고 이동시킨 후 RGB 카메라 평면에 투사
- 단계 5. 회귀 포레스트로 머리 포즈 (R|T)를 얻음
- 단계 10. 형태 계수 C를 출력
5. Experimental results
5.1. Experimental data
본 논문에서는 Biwi Kinect Head Pose Database를 사용하여 AAM(Active Appearance Model) 학습과 테스트를 수행했다. 이 연구의 방법은 기존 AAM과 비교되며 기존 방식에서는 다양한 보기를 가진 모든 사진을 하나의 모델로 학습시킨 반면, 이 연구에서는 머리 포즈를 고려하여 적합한 AAM 모델을 선택한다.
5.2. Result

제안된 방법을 통해 실험한 결과
- Establish facial 3D grid : 약 0.5초 소요
- Head Pose ~ Match : 81 ~ 99 ms 소
성능 비교

- 좌측 이미지 : 원래 문헌의 방법
- 우측 이미지 : 제안된 방법
각 모델의 성능 측정을 위해 다음의 식을 사용하여 오차를 측정한. 비디오 시퀀스에서 뷰 변경과 눈 감김이 있기 때문에, 동공의 거리 대신 두 눈의 내부 모서리 사이의 거리를 정규화로 사용한다.
$$ e = \frac{1}{N\cdot D}\sum_{i=1}^{N}e_{i}, $$
- N : 얼굴 특징의 수
- ei : 추출된 얼굴 특징과 기준사실 사이의 RMS(루트 평균 제곱) 오류
- D : 두 눈의 내부 모서리 사이의 거리
RMS 오류 / 수렴

제안된 방법의 수렴율과 RMS 오류가 원래 문헌의 방법보다 더 우수함을 확인할 수 있다.