Request Rejected
ieeexplore.ieee.org
Abstract
본 논문은 딥러닝 기술을 사용하여 RGB-D 카메라 포즈 추정에 대한 연구를 제시한다. 제안된 네트워크 구조는 시각 정보를 활용하는 컨볼루션 신경망(CNN)과 시간적 정보를 포함하는 장단기 기억(LSTM) 블록, 총 2 가지 구성 요소로 이루어져 있다.
1. CNN
- RGB-D 데이터를 기반으로 한 GoogLeNet 변형으로, 카메라 포즈를 추정하는 특성 중심의 기능을 수행
2. LSTM
- 포즈 추정의 시간적 연속성을 모델링하여 정확도를 높임
또한, 포즈 매개변수의 효과적인 수렴을 지원하는 수정된 Loss Function 도입한다. 실험을 통해 CNN과 LSTM의 조합이 포즈 추정의 정확도를 크게 향상시키며, 네트워크의 파이프라인 구조가 다양한 사용 사례에 대해 유연한 적용을 가능하게 함을 입증한다.
1. Introduction
본 논문은 RGB-D 카메라의 위치와 방향을 결정하기 위해 CNN과 LSTM을 활용하는 포즈 추정 알고리즘의 가능성을 탐구한다. 시각적 단서는 이미지 컨볼루션과 템플릿 창 기반 처리의 일치하는 본성을 통해 CNN으로부터 추출될 수 있으며, 실시간 이미지 시퀀스의 연속적인 포즈 전환은 중첩된 짧은 시퀀스로 분할되어 LSTM 모델과 호환된다.본 연구의 핵심은 CNN과 LSTM을 통합하여 RGB-D 카메라 포즈 추정 문제를 해결할 수 있는지, 그리고 포즈 쿼터니언의 제약을 충족시키기 위한 비용 함수의 수정 가능성을 조사하는 것이다.
2. RELATED WORK
2.1. PoseNet
- GoogLeNet의 구조를 따름
- cascaded inception module 9개, Convolution Layer 3개, Dense Layer 1개로 구성
- GoogLeNet의 출력 → 클래스 레이블
- PoseNet의 출력 → 카메라 포즈 매개변수
- 3차원 공간 좌표(x, y, z)
- 4차원 쿼터니언 방향 <w, x, y, z>
Loss Function
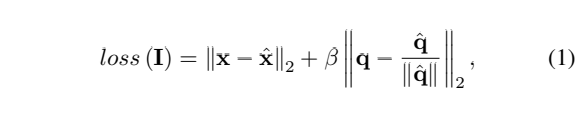
- I : 입력 이미지
- (x, q) : 실제 이동 및 회전(쿼터니언)
- (x^, q^) : 예측된 매개변수
- β : 이동 오류와 방향 오류 사이의 균형을 조정하기 위해 사용되는 하이퍼 파라미터
2.2. LSTM
- Input gate, Forget gate, Output gate 등 으로 구성
- 각각의 가중치 행렬과 편향 행렬에 의해 작용하며 항목별 정보 흐름 제어를 수행
- LSTM 모델 도입의 이점?
- 연속 프레임 내에 내재된 시간적 정보를 활용하는 데 도움을 줌
- 더 정확한 포즈 추정 결과를 생성
3. PROPOSED METHOD
제안된 방법의 네트워크 구조는 PoseNet과 LSTM 모델의 연결된 형태로 이루어져 있다.

- PoseNet
- 각 파이프라인은 여러 개의 Inception 모듈을 포함하는 PoseNet 블록으로 시작
- 이미지의 특징을 추출하며, 각 프레임에 대한 포즈(위치와 방향)를 추정하는 데 사용
- PoseNet 블록은 주어진 입력 시퀀스에서 중요한 시각적 특징을 추출하는 역할을 함
- LSTM
- PoseNet 블록 다음에 위치
- 순차적 데이터 처리에 적합하여, 시간에 걸쳐 발생하는 카메라의 움직임 패턴을 학습하고, 정확도를 향상
- Pipeline
- 연속된 프레임들에 대한 정보를 처리하도록 설계
- 각 프레임은 시간적으로 이전 프레임과 중첩되는데, 이렇게 중첩되는 짧은 시퀀스는 LSTM에 의해 처리
- Input & Output
- Input : 입력 시퀀스를 받아 각 프레임에 대한 카메라 포즈 추정을 수행
- 결과는 ‘intermediate pose output'을 통해 제공되며, 최종 프레임에 대한 'pose output for frame(n)'으로 나타남
3.1. Network Structure
카메라 움직임이 상대적으로 안정적인 경우, 파이프라인의 총 수를 줄일 수 있으며, 이는 단순화뿐만 아니라 과적합을 피하기 위해서도 유용하다. 복잡한 움직임, 특히 여러 교차점을 가진 중첩된 경로나 궤적의 경우, 충분한 양의 훈련 데이터가 제공된다면 파이프라인을 늘리는 것이 일반적으로 추정 정확도를 향상시다.
3.2. Specifications
3.2.1. PoseNet Input
- CNN 아키텍처 기반의 기본 구조 사용
- RGB-D 데이터 수용을 위해 4차원 입력 변형(쿼터니언 시퀀스를 처리할 수 있도록 수정)
3.2.2 LSTM Input/Output
- PoseNet = 기본 포즈 추정기
- LSTM = 추정된 포즈 시퀀스를 처리하는 시간적 필터
- LSTM 모델의 출력은 실제로 전체 네트워크의 최종 출력
- LSTM 입력, 출력 모두 7차원 포즈 벡터가 됨
- Pose : (x, y, z)
- Quaternion : <w, x, y, z>
3.2.3. Loss Function
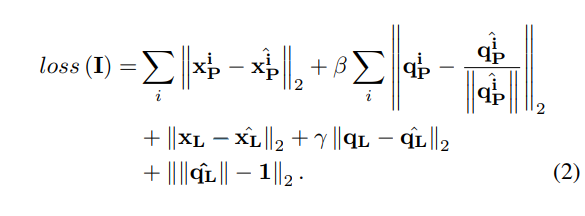
- 예측된 포즈 벡터들은 PoseNet과 LSTM의 출력을 각각 나타내는 두 그룹 (xiP,qiP)과 (xL,qL)로 나뉨
- i : 해당 RGB-D 프레임의 인덱스를 지정
- γ : 이동 오류와 회전 오류 사이의 균형을 유지하기 위한 하이퍼 파라미터
- q^L : 필러링된 출력
PoseNet과 관련된 오류 항을 유지함으로써, 중간 출력들은 훈련 과정 중에 이상적인 결과로 재지향된다. CNN이 특징 기반의 예측 결과를 생성하도록 훈련되고, LSTM은 이로부터 내장된 시간적 증거를 추가로 활용할 수 있게 보장한다.
4. EXPERIMENTS
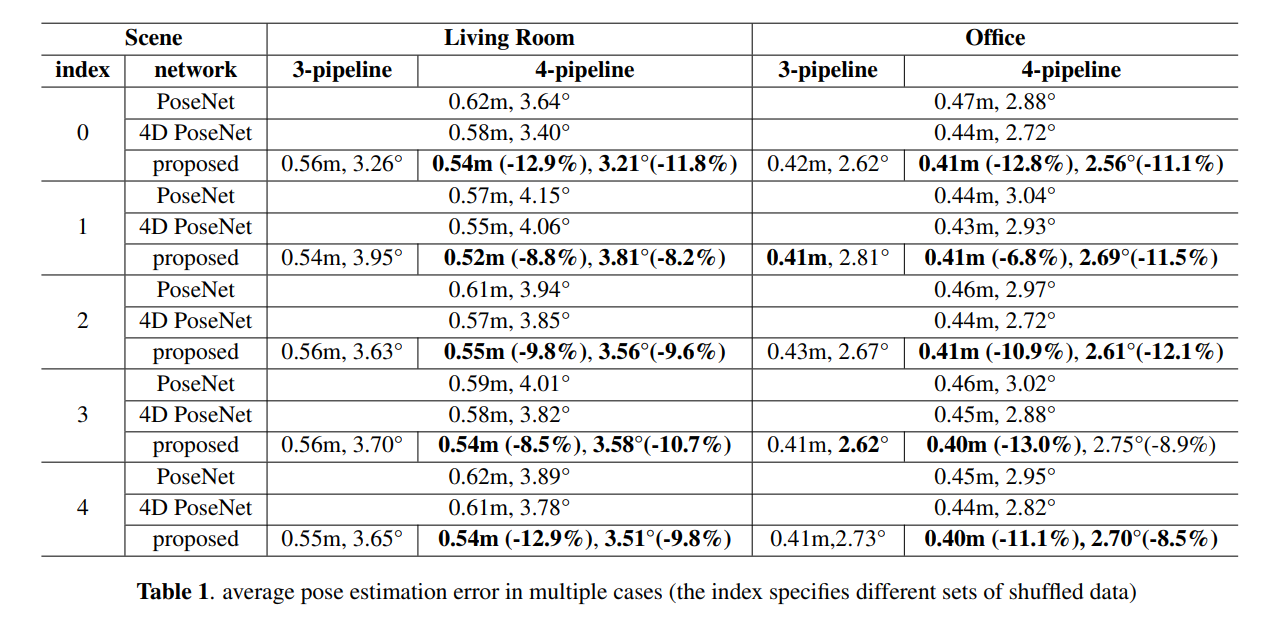
- PoseNet에 비해 포즈 추정 정확도를 8%에서 12% 향상
- 3-파이프라인과 4-파이프라인 결과 간의 비교를 바탕으로, 카메라 움직임과 파이프라인 총 수가 관련되어 있다는 또 다른 가정을 검증할 수 있음
5. CONCLUSION
본 논문에서는 RGB-D 이미지 시퀀스로부터 카메라 포즈 추정 문제를 해결하기 위해 CNN과 LSTM으로 구성된 딥 뉴럴 네트워크를 제시한다. 또한 포즈 매개변수의 본질적인 제약을 더 잘 만족시키기 위한 맞춤형 손실 함수도 제안된다. 실험 결과는 제안된 방법이 포즈 추정 정확도 측면에서 더 높은 성능을 제공할 수 있음을 보여주고, 딥 뉴럴 네트워크가 다양한 시나리오와 모달리티에서 오는 정보를 처리하는 데 탁월한 유연성을 제공할 수 있음을 입증한다.
'논문' 카테고리의 다른 글
| [논문] AAM Based Facial Feature Tracking with Kinect (0) | 2024.03.25 |
|---|---|
| [논문] ImageNet Classification with Deep Convolutional Neural Network (0) | 2024.03.25 |
| Physics-based Deep Learning - Overview (0) | 2024.03.15 |
| [논문] Two-Level Attention-based Fusion Learning for RGB-D Face Recognition (0) | 2024.03.11 |
| [논문] A survey on RGB-D datasets (0) | 2024.03.10 |