ImageNet Classification with Deep Convolutional Neural Networks
Requests for name changes in the electronic proceedings will be accepted with no questions asked. However name changes may cause bibliographic tracking issues. Authors are asked to consider this carefully and discuss it with their co-authors prior to reque
papers.nips.cc
Abstract
ImageNet LSVRC-2010 대회에서 1.2백만 고해상도 이미지를 1000개 클래스로 분류하기 위해 대규모 깊은 컨볼루션 신경망을 훈련시켰다. 이 신경망은 6천만 개의 매개변수와 65만 개의 뉴런을 포함하며, 5개의 Convolution Layer, 일부는 Max Pooling Layer가 뒤따르고, 3개의 FC Layer를 거쳐 1000개에 대한 확률을 구하는 softmax로 구성된다. Overfitting을 방지하기 위해 Drop-out 정규화 기법을 적용하고, non-saturation 뉴런 사용과 GPU에 최적화된 컨볼루션 연산으로 훈련 속도를 향상시켰다. 결과적으로, 이전 최고 기록보다 우수한 37.5%의 top-1 오류율과 17.0%의 top-5 오류율을 달성했다.
※ non-saturation 뉴런 : 활성화 함수가 포화 상태에 도달하지 않아 입력에 따른 출력이 지속적으로 변화할 수 있는 뉴런
1. Introduction
합성곱 신경망(CNN)은 이 복잡한 작업을 처리하기 위한 이상적인 모델로, 큰 데이터셋(ImageNet)에서 뛰어난 성능을 보였다. 이 논문은 ImageNet에서 최고 성능을 달성한 대규모 CNN의 개발과 훈련 과정을 다룬다. 고도로 최적화된 GPU 구현과 과적합 방지 기법을 제시하며, 객체 인식에서의 주요 진전을 보여준다.
2. The Dataset
본 논문에서 제시하는 합성공 신경망 학습에 사용되는 이미지는 일정한 입력 차원을 위해 256×256 해상도로 다운샘플링되며, 훈련 세트의 각 픽셀에서 평균 활동을 빼는 것을 제외하고는 전처리되지 않았다.
3. The Architecture
네트워크의 구조는 다섯 개의 Convolution Layer와 세 개의 Fully Connected Layer로 구성된 총 여덟 개의 학습된 레이어를 포함한다.
3.1 ReLU Nonlinearity
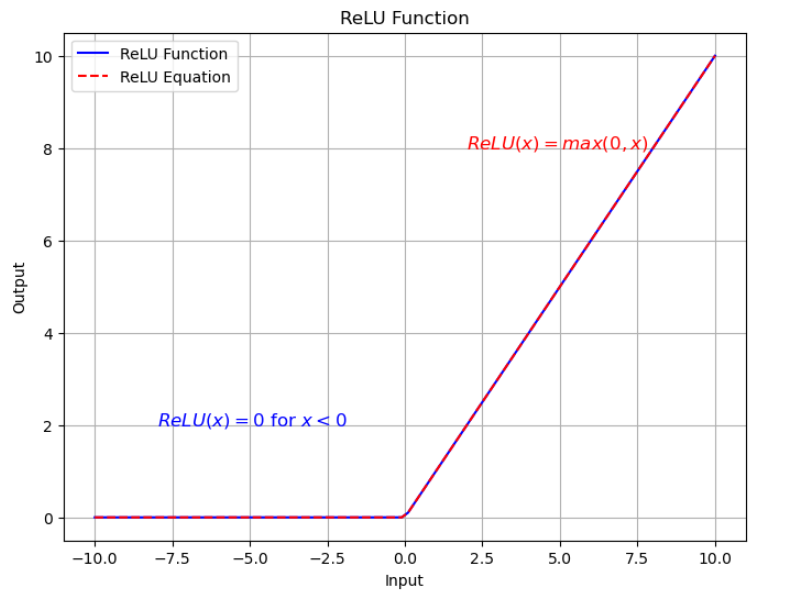
뉴런의 출력을 모델링하는 표준 방법은 $$ f(x) = tahn(x) $$ 또는 $$ f(x) = \frac{1}{1 + e^{-x}} $$ 으로, 이 포화 비선형성 함수는 경사 하강법을 사용한 학습 시간이 max(0, x)의 비포화 비선형성 함수보다 훨씬 느리다. 이와 관련하여 ReLUs(Rectified Linear Units)라는 비포화 비선형성 함수를 사용하는 것이 일반적이다.
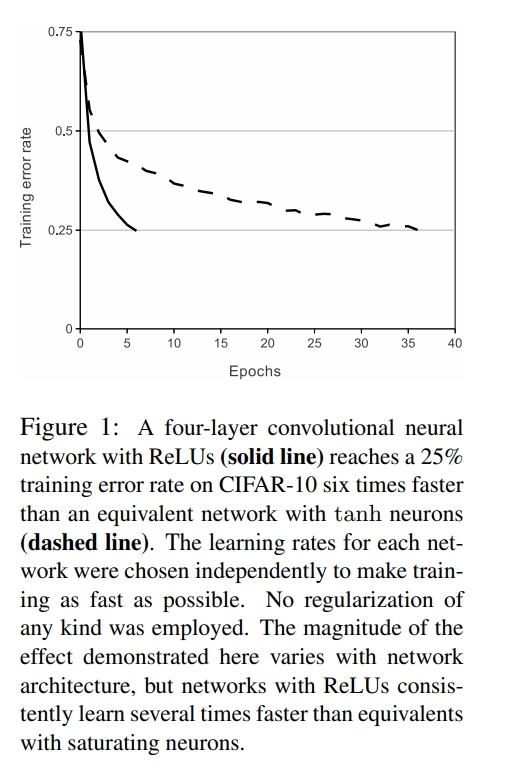
FIgure 1
- ReLU를 사용하는 네 개의 층으로 이루어짐
- 동일한 네트워크에 tanh 을 사용하는 것보다 25%의 훈련 오류율을 여섯 배 빠르게 달성
- 각 트워크의 학습률은 훈련을 가능한 한 빠르게 만들기 위해 독립적으로 선택
- ReLU 함수
3.2 Training on Multiple GPUs
기존에는 단일 GPU를 사용하여 큰 네트워크를 훈련하는 것이 제한되었다. 이에 본 논문에서는 네트워크를 두 개의 GPU로 분산시키고, 각 GPU 간의 병렬화를 위해 특별한 기술을 적용했다. 이 기술은 각 GPU에 절반의 커널을 할당하고 특정 레이어에서만 통신하도록 설정되었다. 이 방식을 통해 top-1과 top-5 오류율을 각각 1.7%와 1.2% 줄일 수 있었으며, 두 개의 GPU로 훈련된 네트워크가 단일 GPU로 훈련된 네트워크보다 더 빠르게 훈련될 수 있었다.
3.3 Local Response Normalization (LRN)
ReLUs는 지역 정규화 방식이 일반화를 향상시킨다는 것을 발견했다. 이 방식은 응답 정규화를 포함하는데, 여기서 ReLU 비선형성을 거친 위치 (x,y)에서 커널 i를 적용하여 계산된 뉴런의 활성을 나타낸다. 응답 정규화는 실제 뉴런에서 발견되는 측면 억제에 영감을 받아, 가까운 커널 활동을 포함하는 항으로 나누는 것을 포함한다. 이때, k, n, α, β와 같은 하이퍼파라미터는 검증 세트를 사용하여 조정된다. 이 정규화는 top-1 및 top-5 오류율을 각각 1.4% 및 1.2% 감소시켜 CIFAR-10과 같은 데이터셋에서 성능을 향상시켰다.
$$ b_{x,y}^{i} = a_{x,y}^{i} /\left ( k + \alpha \sum_{j=max(0, i-n/2)}^{min(N-1, i+n/2)} (a_{x,y}^{j})^{2}) \right)^{\beta} $$
※ 응답 정규화(response normalization) : 컨볼루션 신경망(Convolutional Neural Network)에서 사용되는 한 종류의 정규화 기법, 신경망의 각 뉴런의 활성을 정규화하여 학습의 안정성을 향상시키고 성능을 개선하는 데 도움을 줌
3.4 Overlapping Pooling
CNN의 풀링 레이어는 일반적으로 이웃하는 뉴런 그룹의 출력을 요약하여 다음 레이어에 전달한다. 일반적으로 풀링 유닛 사이의 이웃들은 겹치지 않는다. 풀링 레이어는 풀링 유닛들의 격자로 생각할 수 있으며, 각 풀링 유닛은 특정 위치를 중심으로 한 이웃의 출력을 요약한다. 겹치는 풀링을 사용하면 이웃하는 풀링 유닛들의 출력이 겹치게 되어 더 많은 정보를 전달할 수 있다. 겹치는 풀링을 사용하면 일반적으로 오류율이 감소하는 경향이 있다.

3.5 Overall Architecture
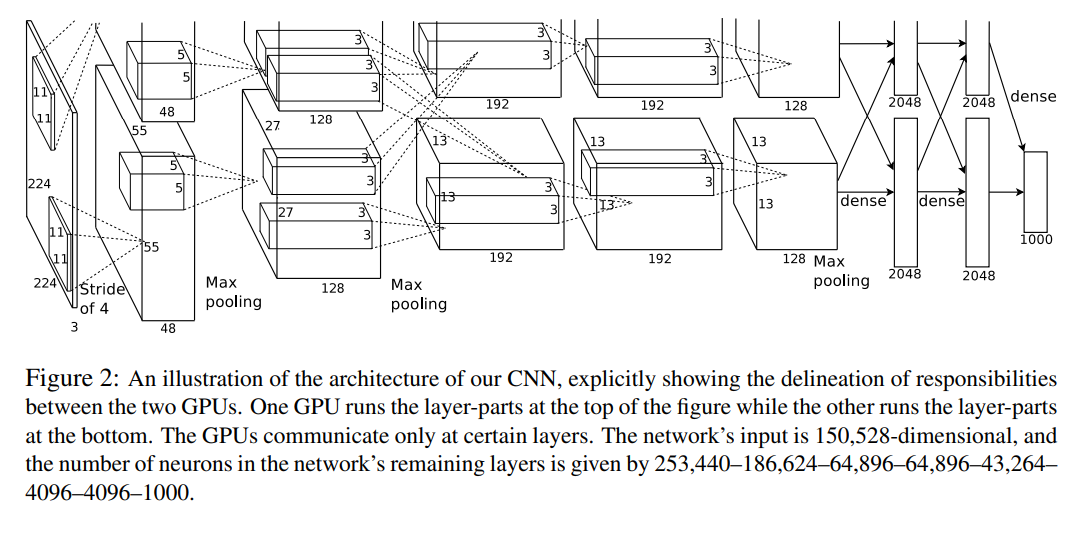
- 총 8개의 가중치를 가진 레이어로 구성
- 처음 다섯 개 → Convolution Layer, 나머지 세 개 → Fully Connected Layer
- 마지막 완전 연결 레이어의 출력은 1000개의 클래스 레이블에 대한 분포를 생성하는 softmax로 구성
- 두 번째, 네 번째 및 다섯 번째 합성곱 레이어의 커널은 이전 레이어에 있는 해당 커널 맵과만 연결됨 → GPU 부분에서 설명한 대로
- 세 번째 합성곱 레이어의 커널은 이전 레이어의 모든 커널 맵과 연결
- LPN은 첫 번째와 두 번째 합성곱 레이어를 따름
- Max-pooling Layer는 LPN 및 다섯 번째 합성곱 레이어 뒤를 따름
CNN의 아키텍처는 Figure 2와 같다. 첫 번째 합성곱 레이어는 224x224x3 크기의 입력 이미지를 11x11x3 크기의 96개의 커널로 필터링하며, 픽셀 간 4픽셀의 stride로 작동한다. 각 GPU는 그림 상단 또는 하단의 레이어 부분을 실행하며, 특정 레이어에서만 통신한다. 네트워크의 입력은 150, 528 차원이며, 나머지 레이어에 있는 뉴런 수는 각각 253, 440, 186, 624, 64, 896, 64, 896, 43, 264, 4096, 4096, 1000 이다.
※ 논문에서 첫 번째 레이어에서 받는 입력의 크기가 224 x 224 x 3 크기의 입력을 받는다고 발표했지만, 이후에 이는 오류라고 227 x 227 x 3 의 크기가 맞다고 정정
4. Reducing Overfitting
4.1 Data Augmentation
이미지 데이터에서 과적합을 줄이는 가장 쉽고 흔한 방법은 레이블을 보존하는 변환을 사용해 데이터셋을 인위적으로 확장하는 것이다. 본 논문에서는 데이터 증강의 두 가지 독특한 형태를 사용한다.
1. 이미지의 변환 & 수평 반전 생성
- 256x256 이미지에서 무작위 224x224 패치(및 그 수평 반전)를 추출
- 추출된 패치로 네트워크를 학습 진행
- Test 진행 시, 네트워크는 네 모서리 패치와 중앙 패치(총 10 개의 패치) 및 그들의 수평 반전을 추출하여 네트워크의 softmax가 10 개의 패치에 대해 내린 예측을 평균
2. 학습 이미지의 RGB 채널 강도를 변경
- RGB 픽셀 값에 대해 PCA(주성분 분석)를 수행
- 각 학습 이미지에, 발견된 주성분의 배수를 추가
$$ [p_{1}, p_{2}, p_{3}][\alpha _{1}\lambda_{1}, \alpha _{2}\lambda_{2}, \alpha _{3}\lambda_{3}]^{T} $$
4.2 Dropout
Dropout은 딥러닝 모델, 특히 신경망에서 과적합을 방지하는 효과적인 정규화 기법이다. 이 방법은 학습 과정 중에 무작위로 일부 뉴런의 출력을 0으로 설정하여, 즉 해당 뉴런을 "무시"하여 네트워크가 일부 특정 뉴런의 존재에 과도하게 의존하는 것을 방지한다. 구체적으로, 각 학습 단계에서 각각의 뉴런은 설정된 확률(일반적으로 0.5)에 따라 활성화되거나 비활성화된다. 본 네트워크 에서는 첫 두 개의 Fully Connected Layer 에서 Dropout을 사용한다.
5. Results
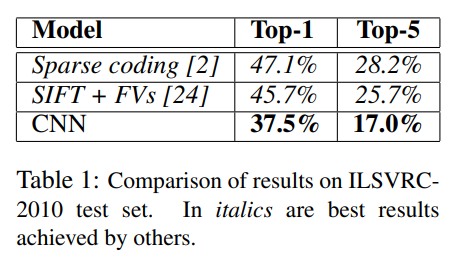
- Table 1 : ILSVRC-2010 에서 top-1 및 top-5 테스트 세트 오류율 각각 37.5%와 17.0% 달성
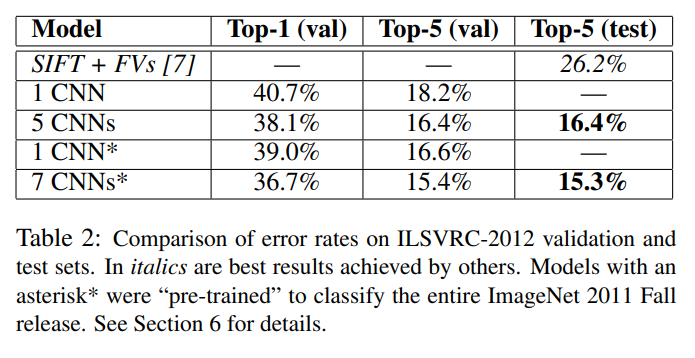
- Table 2 : ILSVRC-2012 검증 및 테스트 세트의 오류율 비교 결과3.5 Overall Architecture