U-Net: Convolutional Networks for Biomedical Image Segmentation
There is large consent that successful training of deep networks requires many thousand annotated training samples. In this paper, we present a network and training strategy that relies on the strong use of data augmentation to use the available annotated
arxiv.org
Abstract
기존의 딥러닝 네트워크의 성공적인 학습을 위해서는 **annotation(주석)**이 달린 방대한 데이터를 필요로 했다. 본 논문에서는 **Data Augmentation(데이터 증강기법)**을 사용하여 이용가능한 데이터 샘플들을 제공해 보다 효율적인 네트워크 학습전략을 제시한다. 이 아키텍처는 **Context(맥락)**를 포착하기 위한 수축 경로와 정밀한 위치 지정을 가능하게 하는 비대칭 확장 경로로 구성되어 있다. 이러한 네트워크 구성은 매우 적은 양의 이미지로부터 이미지 분할(Image Segmentation)을 목적으로 제안된 End-to-End 방식의 Fully-Convolutional Network 기반 모델이다.
Introduction
일반적으로 Convolution Network의 사용은 이미지에 대한 단일 클래스 레이블의 출력인 분류 작업에 있다. 그러나 특히 생체 의료 이미지 처리와 같은 전문적이고 세분화가 필요한 작업에서는 원하는 출력에 대한 Localization 이 포함되어야 한다. 즉, 각 픽셀에 클래스 레이블이 할당되어야 한다. Ciresan는 각 픽셀 주변의 지역 영역(패치)을 제공하여 각 픽셀의 클래스 레이블을 예측하는 슬라이딩 윈도우 설정에서 네트워크를 훈련시키는 방법을 제시했다. 하지만 이 방법에는 다음과 같은 단점이 존재한다.
- 각 패치(이미지의 부분적)마다 네트워크를 별도로 실행하기 때문에 느림
- 위치 정확도 불확실 : Max Pooling을 진행하기 때문에 정보 손실 발생
- Context와 패치 크기 : 작은 패치를 사용하면 지역적인 부분만 확인하기 때문에 분류 및 세분화 정확도 저하
위 문제들을 해결하기 위해, 최근의 접근 방식에서는 여러 레이어의 특징을 고려한 분류기 출력을 제안한다. 이는 네트워크의 여러 레이어에서 추출된 특징을 결합하여 더 넓은 Context를 고려할 수 있게 된다. 이를 통해 위치 정확도와 Context 사용을 동시에 고려하여 성능을 향상시킬 수 있다.
U-Net 구조 특징
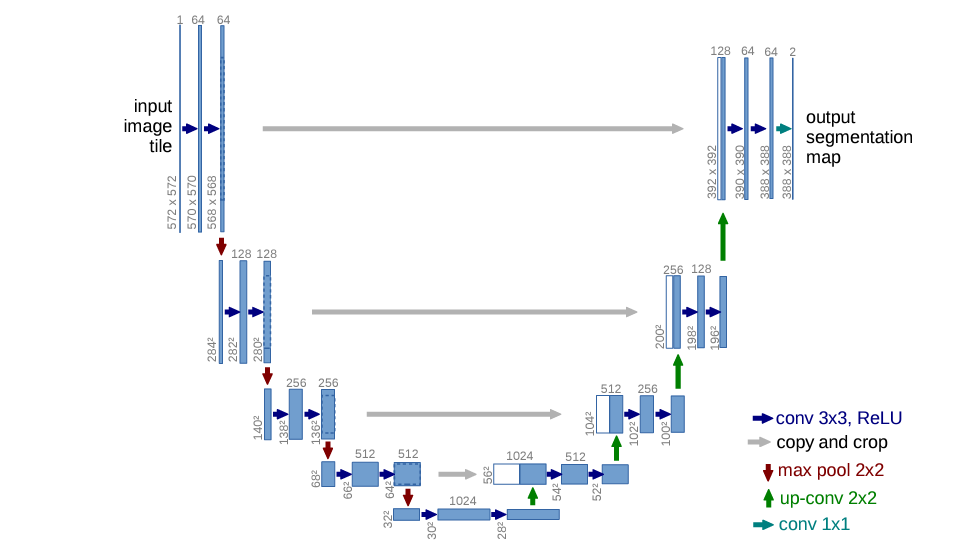
- 각 파란색 상자는 다중 채널 특성 맵에 해당
- 상자 위에 채널 수가 표시
- 상자의 왼쪽 아래 가장자리에 x-y 크기가 제공
- 흰색 상자는 복사된 특성 맵을 나타내고 화살표는 다른 작업을 나타냄
참고 문헌(링크)

수축 단계(Contracting Path)
입력 이미지의 Context 포착을 목적으로 구성
- 수축 경로는 전형적인 합성곱 신경망의 아키텍처를 따름
- 각각이 이어지는 3x3 컨볼루션(패딩되지 않은 컨볼루션)의 반복 적용으로 구성됨
- 각각의 후에는 Rectified Linear Unit(ReLU)과 stride 2를 사용한 2x2 Max Pooling 연산이 있어 다운샘플링
- 각 다운샘플링 단계에서는 특성 채널의 수를 두 배로 늘림
확장 단계(Expanding Path)
세밀한 Localization을 위한 구성, Up-Sampling 얕은 레이어의 특징맵을 결합
- 모든 단계는 특성 맵의 업샘플링을 따름
- 특성 채널 수를 절반으로 줄이는 2x2 Conv ("up-convolution")가 이어짐
- 수축 경로로부터 해당 부분만 잘라낸 특성 맵과 연결하고, 그리고 두 개의 3x3 컨볼루션과 ReLU가 이어짐
- 마지막 레이어에서는 64개의 구성 요소 특성 벡터를 원하는 클래스 수에 매핑하기 위해 1x1 Conv이 사용됨
출력 세그멘테이션 맵의 매끄러운 타일링을 허용하기 위해(그림 2 참조), 모든 2x2 Max Pooling 연산이 짝수 x 및 y 크기의 레이어에 적용되도록 입력 타일 크기를 선택하는 것이 중요하다.
why?
매끄러운 타일링은 출력 세그멘테이션 맵을 여러 타일로 나눌 때 경계 부분에서의 이음새 없이 부드럽게 이어지는 것을 의미한다. 이것을 가능하게 하려면 입력 타일의 크기를 선택할 때, 각 타일에서 모든 2x2 Max Pooling 연산이 짝수 x 및 y 크기의 레이어에 적용되어야 하기 떄문이다.
U-Net 구조의 이점
- 풀링 연산자를 사용하는 대신 업샘플링 연산자로 대체하여 연속적인 레이어를 추가하여 해상도를 증가시킨다.
- Localization을 위해 수축 경로에서의 고해상도 특징과 Up-sampling된 출력이 결합한다.
- 연속적인 합성곱 레이어를 통해 더 정확한 출력을 조립하는 방법을 학습한다.
- 매우 적은 훈련 이미지를 사용하더라도 네트워크는 더 정밀한 세분화를 수행할 수 있게 한다.
Details
첫째로, 업샘플링 부분에서 많은 수의 특성 채널을 사용한다는 점을 강조하고 있다. 이는 네트워크가 고해상도 레이어로 컨텍스트 정보를 전파할 수 있게 한다. 이러한 수정으로 인해 네트워크의 확장 경로는 수축 경로와 거의 대칭이 되어 U자 형태의 아키텍처를 형성하게 된다.
둘째로, 이 네트워크는 완전히 연결된 레이어를 사용하지 않으며(즉, 입출력이 FC와 달리 전부 연결되어 있지 않다), 각 합성곱의 유효한 부분만 사용한다. (이미지의 각 부분에 대해 필터가 적되고, 출력은 이미지의 해당 부분만큼만 생성) 따라서 세그멘테이션 맵에는 입력 이미지의 전체 context가 사용 가능한 픽셀만 포함된다.
이로 인해 임의의 큰 이미지에 대한 부드러운 세분화가 가능하며, 이를 겹치는 타일 전략을 통해 수행할 수 있다. 겹치는 타일 전략은 이미지를 격자로 나누어 각 타일에 대해 네트워크를 적용한 후 겹쳐서 결과를 얻는 방법으로, 이렇게 함으로써 이미지의 가장자리 픽셀을 예측하기 위해 누락된 Context는 입력 이미지를 반사하여 외삽된다.
Overlap Tile Strategy

U-Net 구조에서 이미지의 크기가 큰 경우 이미지를 자른 후 각 이미지에 해당하는 Segmentation을 진행해야 한다. U-Net은 Input과 Output의 이미지 크기가 다르기 때문에 위 그림에서 처럼 파란색 영역을 Input으로 넣으면 노란색 영역이 Output으로 추출된다. 겹치는 부분이 존재하도록 이미지를 자르고 Segmentation하기 때문에 Overlap Tile 전략이라고 논문에서는 지칭한다.
참고 자료(출처)

Data Augmentation

- 매우 적은 훈련 데이터로 인해 Data Augmentation 적용(탄성 변형)
- 3x3 격자에 무작위 변위 벡터를 사용하여 부드러운 변형을 생성
- 변위는 10픽셀 표준 편차를 갖는 가우시안 분포에서 sampling
- pixel 당 변위는 이차 보간법을 사용하여 계산됨
- 수축 경로 끝에 있는 Dropout Layer는 추가적인 암묵적 데이터 증강을 수행
Weighted Loss

- 세포 사이의 분리 배경 레이블에 큰 가중치를 부여하는 가중 손실의 사용을 제안했다.
- 각 픽셀이 경계와 얼마나 가까운지에 따른 Weight-Map을 만들고 학습할 때 경계에 가까운 픽셀의 Loss를 Weight-Map에 비례하게 증가 시킴으로써 경계를 잘 학습하도록 설계했다.
- (a) 원본 이미지, (b) GT Segmentation, (c) generated segmentation, (d) weighted loss adapt
Training
padding 되지 않은 convolution으로 인해 출력 이미지는 입력보다 상수 폭의 테두리 폭이 작다. overhead(처리시간)를 최소화하고 GPU 메모리를 최대한 활용하기 위해, 큰 입력 타일을 큰 배치 크기보다 선호하고 따라서 배치 크기를 단일 이미지로 줄인다. 따라서, 높은 모멘텀(0.99)을 사용하여 이전에 기록된 훈련 샘플의 많은 수가 현재 최적화 단계에서의 업데이트를 결정하도록 한다.
큰 입력 타일을 큰 배치 크기보다 선호한다. why?
→ 입력 데이터가 큰 경우 더 많은 정보가 포함될 수 있어 학습의 품질을 향상시킬 수 있기 때문이다.
배치 크기를 단일 이미지로 줄인다. why?
→ 입력 타일의 크기를 크게하기로 결정했기 때문에 이 경우에는 배치에 포함되는 이미지 수를 줄이는 것이 좋다. 따라서 배치 크기를 단일 이미지로 줄임으로써, 각 훈련 단계에서 네트워크가 하나의 큰 입력 타일만 처리하도록 한다.
손실 함수(Loss Function)
- 최종 특성 맵에 대한 픽셀별 소프트맥스와 교차 엔트로피를 사용하여 계산한다.
- 소프트맥스 함수는 각 클래스에 대한 확률을 계산
- 교차 엔트로피 손실 함수는 예측과 실제 레이블 간의 차이를 측정하여 네트워크의 성능을 평가
- 또한, 가중치 맵을 사용하여 특정 픽셀에 더 중요성을 부여
pl : 각 픽셀의 실제 레이블
w(x) : 훈련 중에 일부 픽셀에 더 중요성을 부여하기 위해 도입한 가중치 맵
wc : 클래스 빈도를 균형잡기 위한 가중치 맵
w0 : 초기 가중치
d1 : 가장 가까운 셀 경계까지의 거리
d2 : 두 번째로 가까운 셀 경계까지의 거리
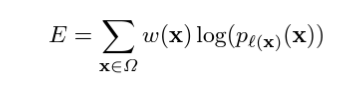

w0(초기 가중치)
이상적으로 초기 가중치는 각 피쳐 맵이 네트워크에서 대략적으로 단위 분산을 가지도록 조정되어야 한다. 아키
텍처를 가진 네트워크의 경우(교대로 이루어진 합성곱 및 ReLU 레이어), 이는 초기 가중치를 평균이 0이고 표준 편
차가 2/N인 가우시안 분포에서 추출함으로써 달성할 수 있다. 여기서 N은 하나의 뉴런의 입력 노드 수를 나타낸다.
ex)
이전 레이어에서 64개의 Feature channel과 3x3 Conv의 경우 N : 9 * 64 = 576
Experiment
2012 ISBI EM Segmentation Challenge

- 왜곡 오차(Warping Error): 예측된 세그멘테이션 맵과 실제 세그멘테이션 맵 간의 왜곡 정도를 나타내는 지표
- 랜드 오차(Rand Error): 예측된 세그멘테이션 맵과 실제 세그멘테이션 맵 간의 일치 정도를 나타내는 지표
- 픽셀 오차(Pixel Error): 예측된 세그멘테이션 맵과 실제 세그멘테이션 맵 간의 픽셀별 오차를 나타내는 지표
2015 ISBI Cell Tracking Challenge

- PhC-U373 데이터 셋에 대해 Average IOU(intersection over union) 92% 달성
- DIC-HeLa 데이터 셋에 대해 Average IOU(intersection over union) 77.5% 달성
- 당시 segmentation 분야에서 SOTA 알고리즘
Conclusion
U-Net 아키텍처는 매우 다양한 생체 의학 세분화 응용 프로그램에서 매우 우수한 성능을 달성했다. 탄성 변형을 통한 데이터 증강 덕분에 매우 적은 양의 주석이 달린 이미지만 필요하며, NVidia Titan GPU(6GB)에서 단 10시간의 매우 합리적인 훈련 시간만으로도 충분하다. 전체 Caffe[6] 기반의 구현과 훈련된 네트워크를 제공한다.
'논문' 카테고리의 다른 글
| [논문] RGB-D camera pose estimation using deep neural network (0) | 2024.03.18 |
|---|---|
| Physics-based Deep Learning - Overview (0) | 2024.03.15 |
| [논문] Two-Level Attention-based Fusion Learning for RGB-D Face Recognition (0) | 2024.03.11 |
| [논문] A survey on RGB-D datasets (0) | 2024.03.10 |
| Physics-based Deep Learning - Introduction (0) | 2024.03.07 |