F1 점수(F1 Score)는 분류 작업에서 정밀도(Precision)와 재현율(Recall)의 조화 평균을 사용하여 모델의 정확성을 평가하는 지표다. 이 지표는 데이터셋에 불균형이 있을 때, 즉 어떤 클래스의 샘플이 다른 클래스 샘플 수 보다 훨씬 많아 불균형을 이룰 때 유용하다. F1 점수는 0부터 1 사이의 값으로 표현되며, 1에 가까울수록 모델의 성능이 뛰어남을 의미한다.
※ 조화 평균 : 주어진 수들의 역수의 산술 평균의 역수를 말한다. 평균적인 변화율을 구할 때에 주로 사용
F1 Score expression
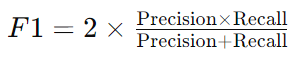
※ 정밀도(Precision) : 모델이 양성이라고 예측한 것들 중 실제로 양성인 비율
※ 재현율(Recall) : 실제 양성 중 모델이 양성으로 올바르게 예측한 비율


- True Positive (TP, 진짜 양성): 모델이 양성이라고 예측하고 실제로 양성인 경우의 수
- False Positive (FP, 거짓 양성): 모델이 양성이라고 예측했지만 실제로는 음성인 경우의 수
- True Negative (TN, 진짜 음성): 모델이 음성이라고 예측하고 실제로 음성인 경우의 수
- False Negative (FN, 거짓 음성): 모델이 음성이라고 예측했지만 실제로는 양성인 경우의 수
Example
어떤 질병을 진단하는 분류 모델의 성능을 평가하기 위한 F1 점수를 계산해보자. 이 모델은 환자가 질병에 걸렸는지(양성) 아닌지(음성)를 예측한다. 모델의 성능을 평가하기 위해 다음과 같은 결과를 얻었다고 가정해 보자.
- TP : 80
- FP : 20
- TN : 90
- FN : 10
Precision = 80 / 80 + 20 = 0.8
Recall = 80 / 80 + 10 ≈ 0.89
F1 = 2 x 0.8 x 0.89 / (0.8 + 0.89) ≈ 0.712 / 1.69 ≈ 0.84
따라서, F1 Score는 약 0.84임을 알 수 있다. 모델의 정밀도와 재현율이 상대적으로 높으며, 두 지표 사이에 균형이 잘 맞춰져 있다는 것을 보아 좋은 성능 지표를 띄고 있다.
'딥러닝' 카테고리의 다른 글
| L1 Loss & L2 Loss (0) | 2024.03.22 |
|---|